배경 및 목표
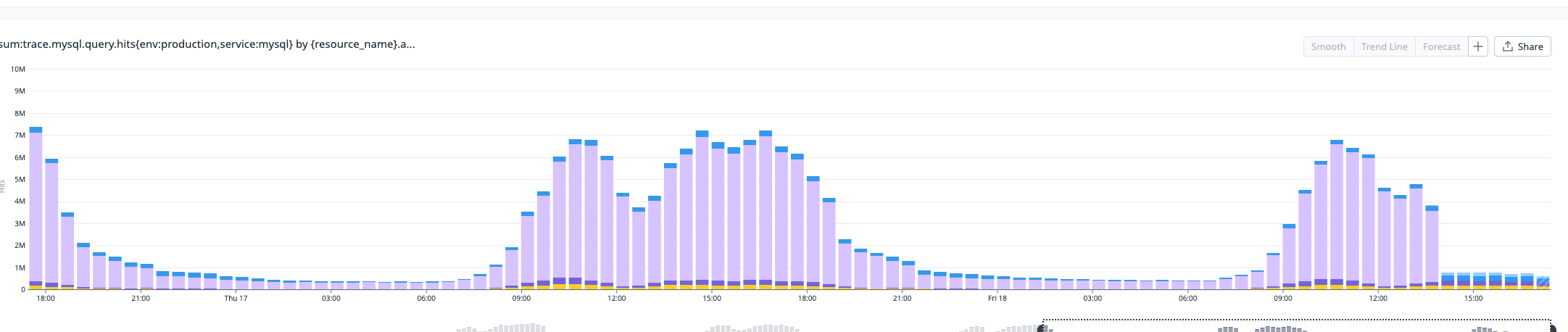
특정 페이지에서 DB CPU가 50~60%까지 상승하여 전체 서비스 응답에 영향을 주고 있었습니다. 모니터링 결과, 두 가지 원인이 확인되었습니다.
- N건을 단건 쿼리로 조회 (루프 안에서 SELECT N번 실행)
- 3초 주기 polling에서 불필요한 COUNT 쿼리가 매번 실행
개별 쿼리는 가벼워 보이지만, 동시 접속자가 많아지면 누적되어 심각한 부하를 만들고 있었습니다.
목표
- 조회로 인한 Reader DB CPU 부하를 낮춰 전체 서비스 응답을 안정화한다.
- 동시 접속자가 늘어도 쿼리 수가 누적되지 않도록 조회 횟수를 최소화한다.
해결 방법과 해결 후보군
1. IN절 벌크 조회 + 메모리 groupBy
N건 단건 쿼리를 1건의 IN절 벌크 쿼리로 변환했습니다.
// ❌ 기존: N번 단건 쿼리
memberIds.forEach { id ->
val result = repository.findById(id) // SELECT ... WHERE id = ?
}
// ✅ 개선: 1번 IN절 벌크
val results = repository.findAllByIdIn(memberIds) // SELECT ... WHERE id IN (?, ?, ...)
val grouped = results.groupBy { it.memberId } // 메모리에서 조합해결 후보군: 조합을 어디서 할 것인가
| 후보 | 설명 | 채택 여부 |
|---|---|---|
DB에서 GROUP BY | 쿼리 한 번에 그룹핑까지 | ❌ DB 부하를 줄이는 것이 목적인데 연산을 다시 DB에 부담 |
앱 메모리 groupBy | 벌크 조회 후 애플리케이션에서 조합 | ✅ 이미 조회한 데이터 가공은 추가 DB 부하 0 |
DB 부하를 줄이는 것이 목적이었기 때문에, 이미 조회된 데이터를 애플리케이션 메모리에서 조합하는 방식을 채택했습니다.
2. COUNT 쿼리 제거
3초 주기 polling에서 페이지네이션을 위해 실행하던 COUNT 쿼리를 컬렉션의 .size()로 대체했습니다.
// ❌ 기존: 매 polling마다 COUNT 쿼리 실행
val totalCount = repository.count(condition) // SELECT COUNT(*) ...
// ✅ 개선: 이미 조회된 데이터의 크기 활용
val totalCount = results.sizepolling 주기가 3초로 짧았기 때문에, 이 COUNT 쿼리가 생각보다 큰 누적 부하를 만들고 있었습니다.

결과
| 지표 | 기존 | 개선 |
|---|---|---|
| 쿼리 수 | 201개 | 3개 (98% 감소) |
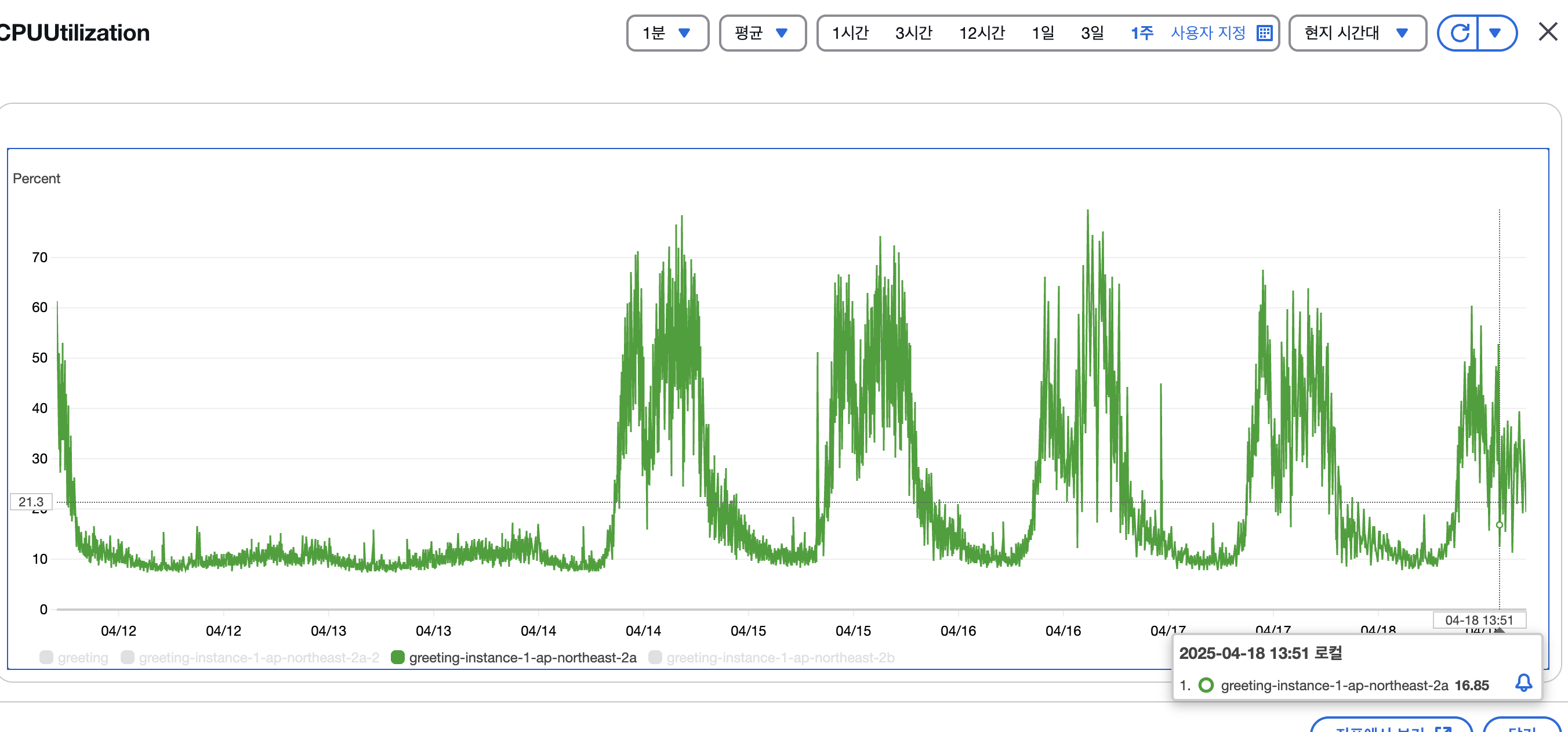
| Reader CPU | 50~60% | 30~40% |
모니터링
- 2개의 reader 인스턴스 기준 평균 CPU 사용량 50
60% → 3040%로 감소 확인
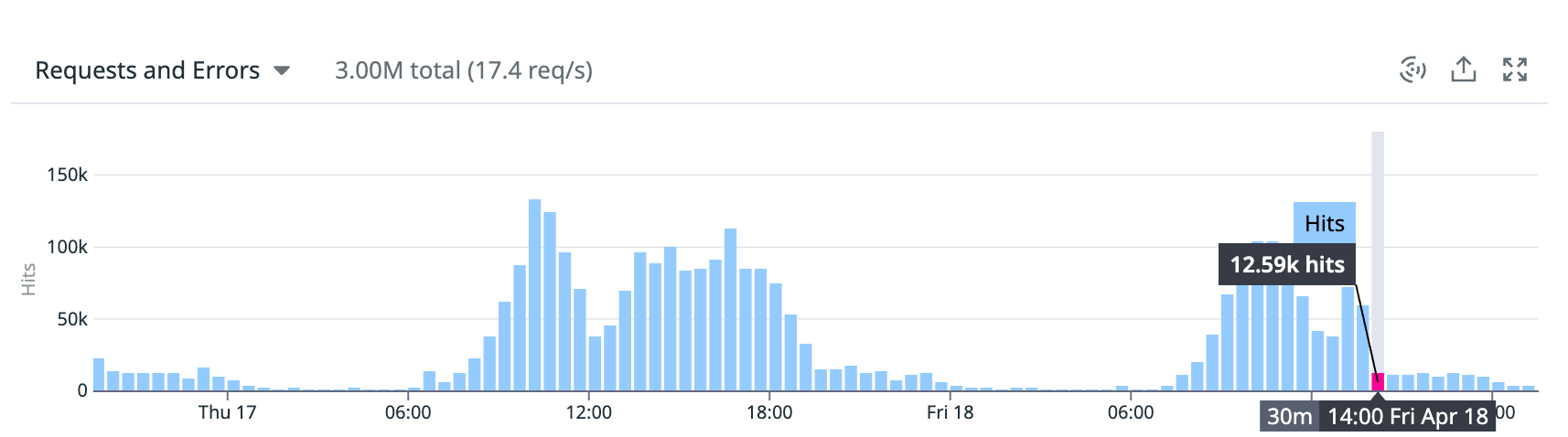
- Top5 성능 병목 쿼리에서 COUNT 쿼리 완전 제거, 개선된 쿼리 요청 횟수 확인